
服务器GPU知识手册
服务器GPU知识手册
GPU简介
GPU,Graphic Processing Unit图形处理器,专门处理图形核心处理器,90%的ALU运算单元,5%的Control控制单元,5%的Cache缓存单元,目前服务器GPU卡用于大模型的训练和推理
GPU的PLX三种拓扑
- Balance拓扑:GPU直通虚拟化,适合中/小规模深度学习模型,推理,公有云和HPC
- Common拓扑:AI训练性能优异,适用于多数的深度学习训练场景
- Casecade拓扑:部分AI训练模型性能最优,适用于多参数模型的大规模深度学习训练场景
GPU的核心参数说明
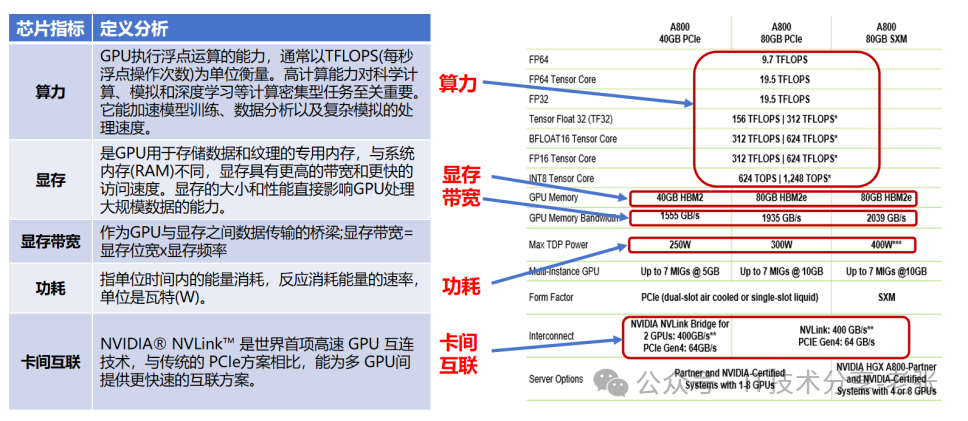
相关名词解释
HBM:High Bandwidth Memory显存,是一种高带宽的3D堆叠内存技术,实现更高的数据传输速率和更低的功耗
HGX:High-Performance GPU extended,是一个计算平台通过NVLink和NVSwitch将多个GPU串连起来提供强大的AI运算能力,A800模组底板,delta板+nvswitch+SXM=HGX
DGX:Data Center GPU数据中心,AI超级计算机硬件配置是固定的,设计是开箱即用
SXM:Tesla Scalable X-Module是NVIDIA Tesla GPU的一种物理封装形式,SXM GPU通常具有更高的功率和性能,支持多GPU扩展,通过NVLink技术实现GPU之间的高速通信
算力理论值计算
TFLOPS,即每秒浮点运算次数
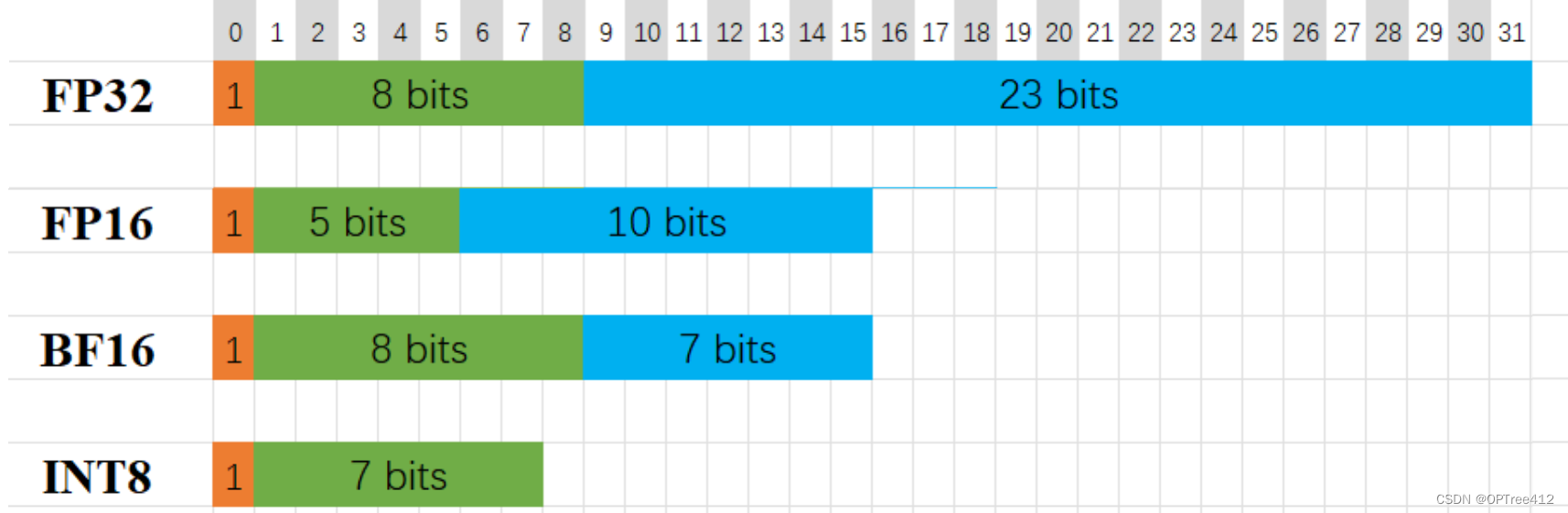
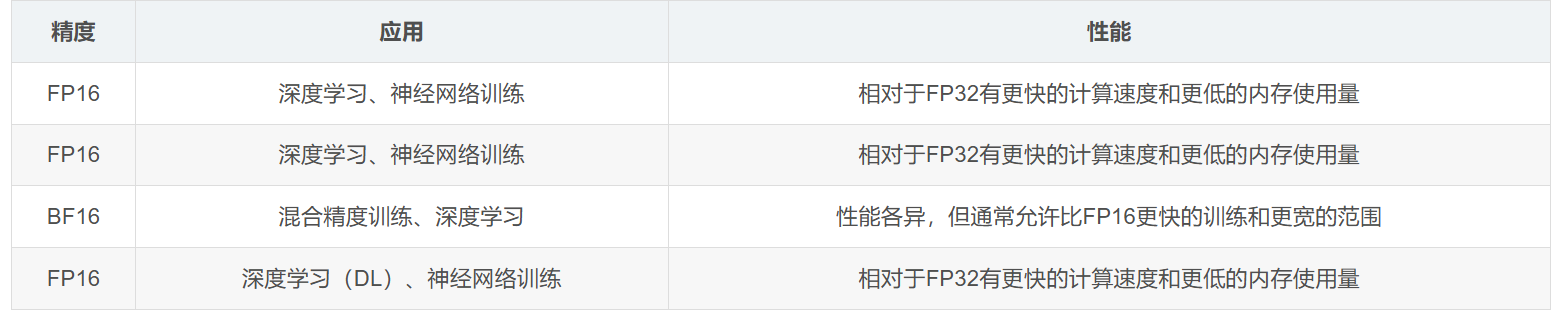
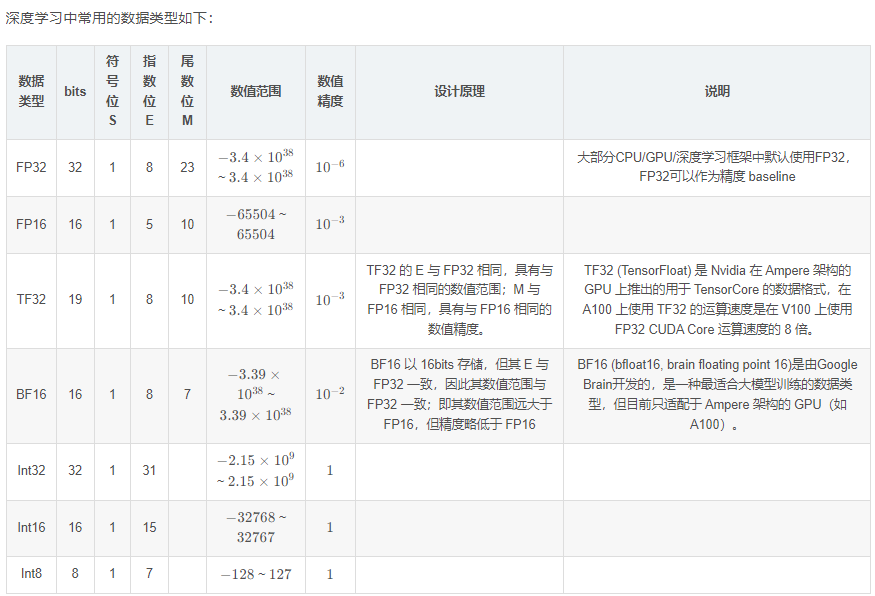
通过降低精度而加快模型训练速度、降低显存占用率的方法——混合精度,使用较低精度的浮点数来表示神经网络中的权重和激活值,从而减少内存使用和计算开销,进而加速训练过程。
算力计算公式:Flops=CPU核数单核主频CPU单个周期浮点计算能力
TFLOPS:TFLOPS是每秒执行的万亿次浮点运算。这是衡量计算性能的传统方式,尤其用于需要大量浮点计算的任务,如图形处理和科学计算。
TOPS:TOPS是每秒执行的万亿次运算。这个术语更常用于衡量AI和机器学习硬件的性能,因为这些任务通常包括大量的整数和固定点运算,而不是传统的浮点运算。 TOPS特别适用于评估深度学习推理任务的性能。
总的来说,TFLOPS更多地关注浮点运算性能,而TOPS则涵盖了更广泛的运算类型,更适用于AI和深度学习应用
英伟达GPU常见的各种核心
CUDA Core
英伟达GPU的参数中,最常看到的核心类型。Nvidia通常用最小的运算单元表示自己的运算能力,CUDA Core 指的是一个执行基础运算的处理元件。我们所说的CUDA Core数量,通常对应的是 FP32 计算单元的数量。Tensor Core
核心特别大,用于机器学习加速,它可以把整个矩阵都载入寄存器中批量运算,实现十几倍的效率提升,从Volta 架构发布以来,奠定了英伟达在AI训练的领军地位,每次升级都有新支持的数据类型。RT Cores
正常数据中心级的GPU核心是没有RT Core的,主要是消费级显卡才为光线追踪运算添加了RT Cores,考虑到芯片的空间有限,每个SM里面只有1个光追核心(为此还砍掉了大部分的FP64)。可以极大地提升了游戏渲染效率。
GPU-GPU的经典互联方案NVLink等技术解析
Nvlink是英伟达私有的芯片互联技术,通常用于GPU之间或者GPU到CPU,Nv Switch是基于Nvlink技术的芯片或者类似交换机的设备,在主机内部NvSwitch是芯片,跨节点互联就是搭载Nv switch芯片的独立网络设备。历代Nvlink的版本和速率变化如下:
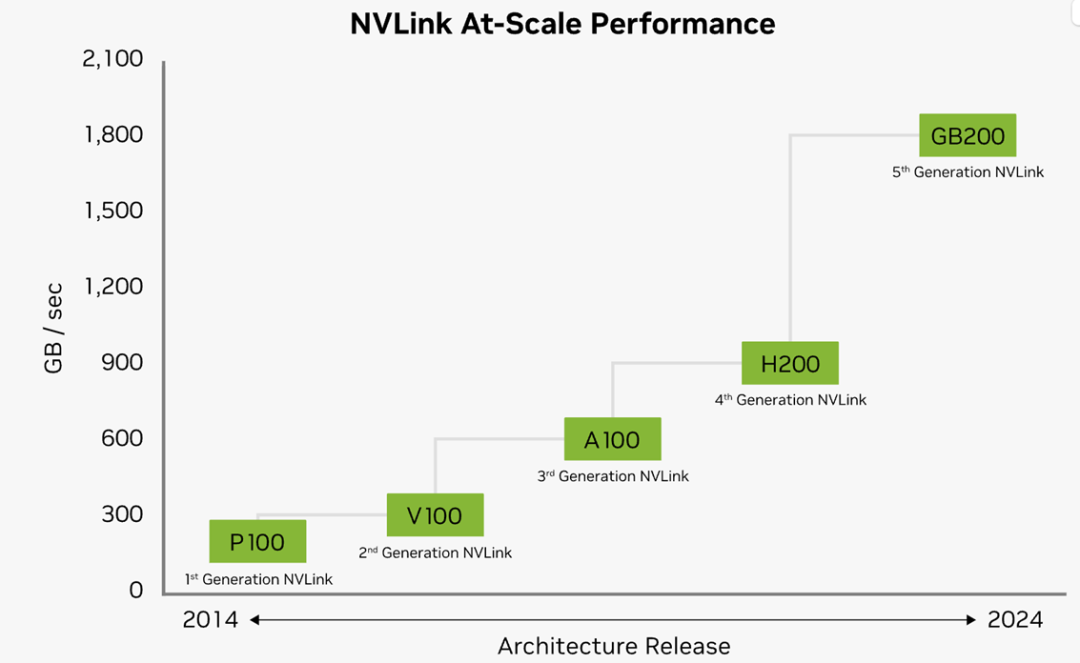
Nvidia GPU互联技术最新的是NVLink5.0,与前代4.0相比通道数不变,速率翻倍至1.8TB/s
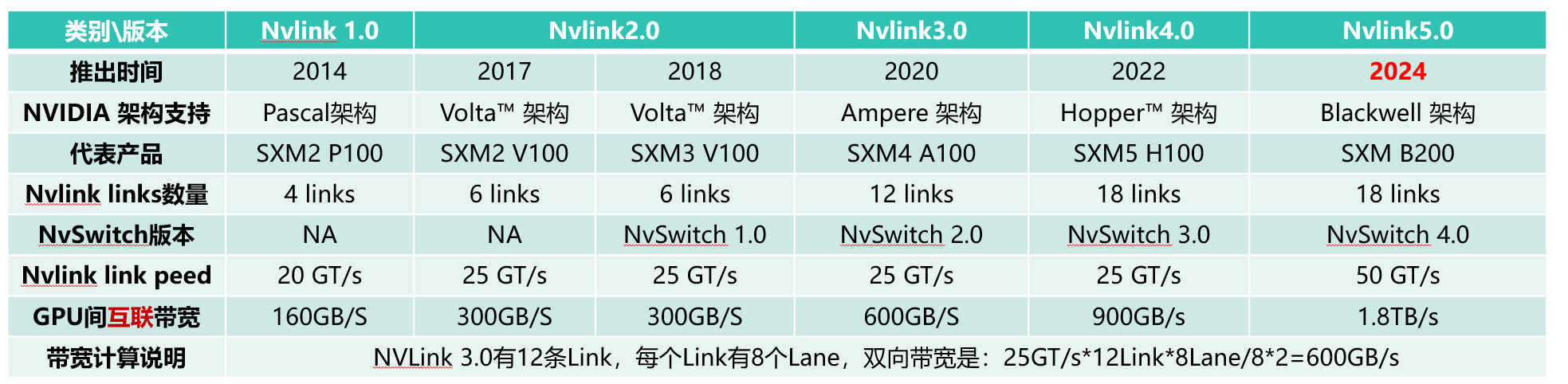
2024年,Blackwell架构的B200正式发布,NVLink和NVSwitch芯片分别来到5.0和4.0的版本,单条链路速率翻倍来到单向50GB/s,数量还是18条,GPU间的互联带宽翻倍至1.8TB/s,8个GPU对应2个NVswitch芯片,每个NvSwitch芯片拥有72个NVLink5.0接口,每个GPU用9条NVLink和2个NVSwitch芯片互联,如下图所示
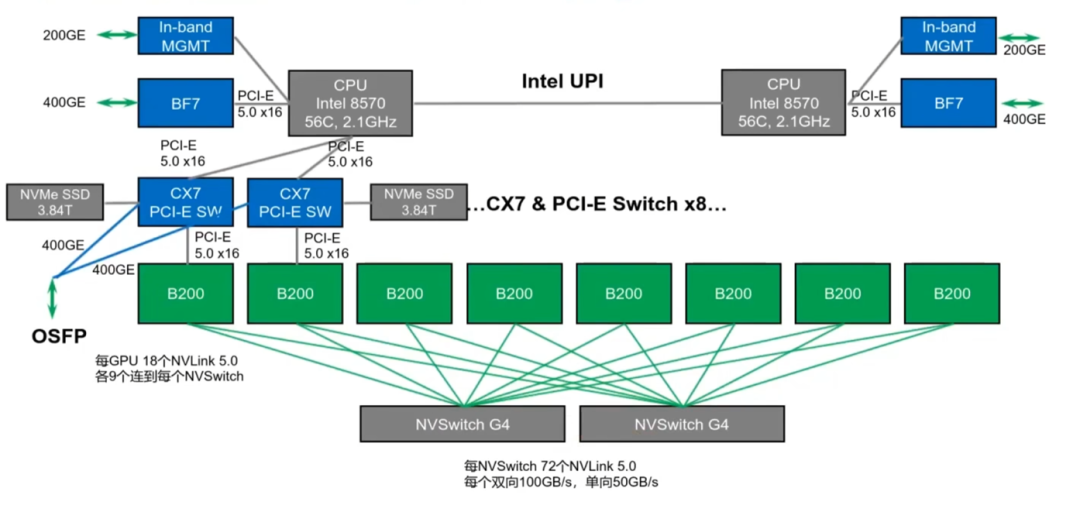
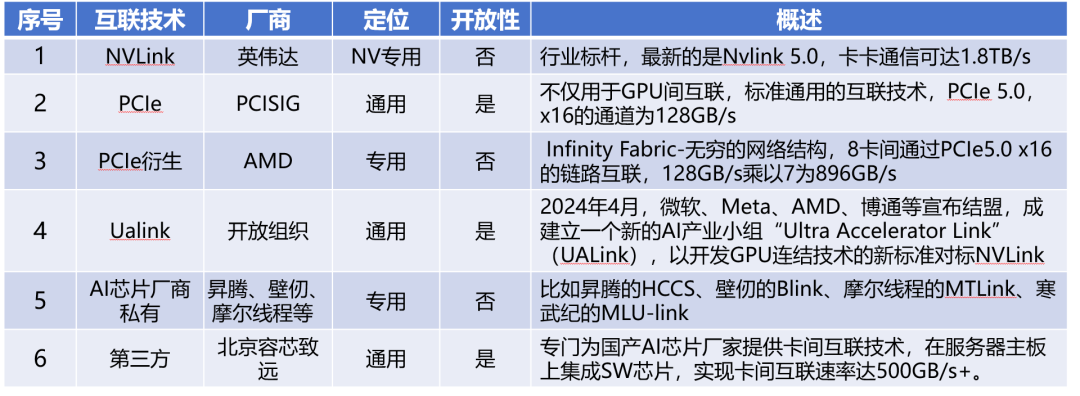
GPU基础环境安装
查看GPU信息
1 | #查看GPU型号 |
nvidia驱动下载
安装CUDA
Nvidia-smi(System Management Interface SMI)监控管理工具
这个命令会报告系统中每个GPU的基本监控数据和硬件参数,配置数据

参考链接:https://developer.nvidia.com/system-management-interface
GPU测试可以参考U盘环境介绍.pdf
Shoc-master
The Scalable HeterOgeneous Computing SHOC单双精度浮点型算力测试,基于GEMM,FFT,Stencil等计算模式,综合CUDA与OpenCL,MPI方式进行GPU算力计算(兼容cuda12之前版本)
Cuda-samples cuda测试用例
#测试带宽H2D
tar -zxvf cuda-samples-11.8.tar.gz
cd cuda-samples-11.8/Samples/1_Utilities/bandwidthTest/
make
单卡./bandwidthTest >> bandwidthTest.log
全卡./bandwidthTest -device=all >> bandwidthTest_all.log
#Bandwidth测试—P2P Bandwidth
cd /cuda-samples-12.2/Samples/5_Domain_Specific/p2pBandwidthLatencyTest/
make
./ p2pBandwidthLatencyTest
H800参考值:400GB/s,达到80%即可
H100参考值:900GB/s,达到80%即可
参考链接:https://github.com/NVIDIA/cuda-samples/tree/master
gpu_burn压测
针对多GPU的压测程序,使用CUDA程序API,每个GPU分配一个进程,一个进程用于跟踪GPU的温度(可用情况下),另一个进程用于报告进度。每个进程分配90%的可用GPU内存,初始化2个随机的2048*2048矩阵,并持续对它们执行高效的CUBLAS矩阵乘法例程,并将结果存储在分配的内存中。浮点数和双精度数均支持。通过将新计算的结果与GPU上先前的计算结果进行比较来检查计算的正确性。这样,GPU始终处于100%繁忙状态,而CPU处于空闲状态。错误计算的数量将返回CPU,并与迄今为止执行的操作数量和GPU温度一起报告给用户。
三天:./gpu_burn 259200
压测一周:nohup ./gpu_burn 604800 &
抓取GPU压测温度功耗:nvidia-smi -l 10 --format=csv --filename=report.csv --query-gpu=timestamp,name,temperature.gpu,power.draw
最后查看cat /var/log/messages | grep -iE "error|fail|warn"
Dmesg | grep -iE "error|fail|warn"
参考链接:https://github.com/wilicc/gpu-burn
stream_vectorized_double_test
nvidia提供的基于CUDA优化的STREAM测试工具,测试单个GPU的显存带宽
参考链接:https://www.cs.virginia.edu/stream/
Peak tops
nvidia提供的算力测试工具,tensor实现FP8,INT8,FP16,BF16,TF32;FFMA实现FP32(只兼容hoper架构)
clublasMatmulBench
NVIDIA CUDA Basic Linear Algebra(cuBLAS)库提供,用于测试单个GPU的general matrix multiplication(GEMM)性能
参考链接:https://developer.nvidia.com/cublas
nvbandwidth
nvbandwidth是一个用于测量NVIDIA GPU带宽的工具,用于测量不同链接上各种memcpy模式下的带宽
单向测试,测量从CPU到GPU的带宽
双向测试,同时测量两个方向上的带宽
参考链接:https://github.com/NVIDIA/nvbandwidth
NCCL测试
nccl库测试说明https://mp.weixin.qq.com/s/3lrLSYe7JhalTcXjpFQ0dA
batchCUBLAS
Batch CUBLAS(CUDA Basic Linear Algebra Subprograms)测试是用于评估 NVIDIA GPU 在执行线性代数运算时的性能的工具。CUBLAS 是 NVIDIA 提供的一个库,它实现了在 GPU 上运行的基本线性代数运算,比如矩阵乘法、向量点乘等。
参考链接:https://github.com/NVIDIA/cuda-samples/blob/master/Samples/4_CUDA_Libraries/batchCUBLAS
Unixbench测试
Unixbench 是一个基准测试工具,它通过一系列测试来评估 Unix 系统的性能。Unixbench 测试套件包括对 CPU、内存、磁盘 I/O、系统调用等的测试。maxCopies 是 Unixbench 中的一个参数,它用于控制测试中数据复制的最大次数。
软件包链接:https://soft.lnmp.com/test/unixbench/
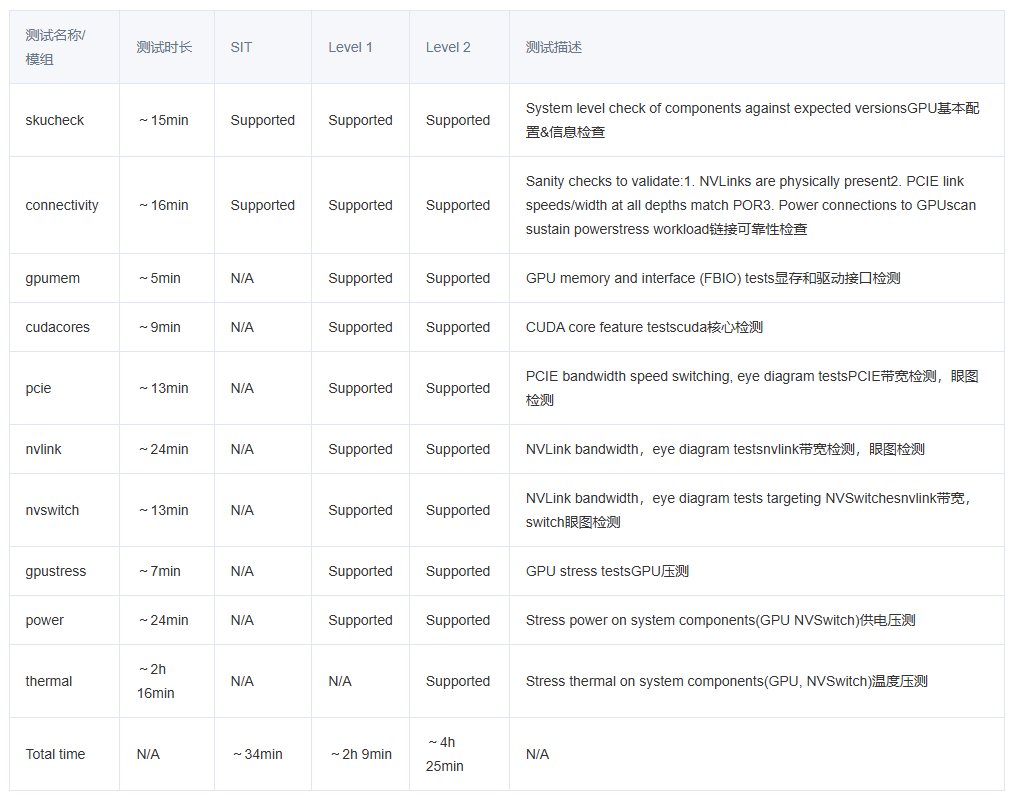
Dcgmi diag -r 4
DCGM Diagnostics提供了系统级的英伟达GPU卡检测工具,采用level1,level2,level3和level4的诊断级别,检测软件,pcie+nvlink,GPU memory,Memory Bandwidth, Diagnostics,Targeted Stress,Targeted Power,Memory Stress,Input EDPp方面的检测
参考链接:http://docs.nvidia.com/datacenter/dcgm/latest/user-guide/dcgm-diagnostics.html
- p2pBandwidthLatencyTest
测试使用cuda在GPU与GPU直接数据传输的效率,验收新服务器的时候常用
DCGM实现GPU的性能分析
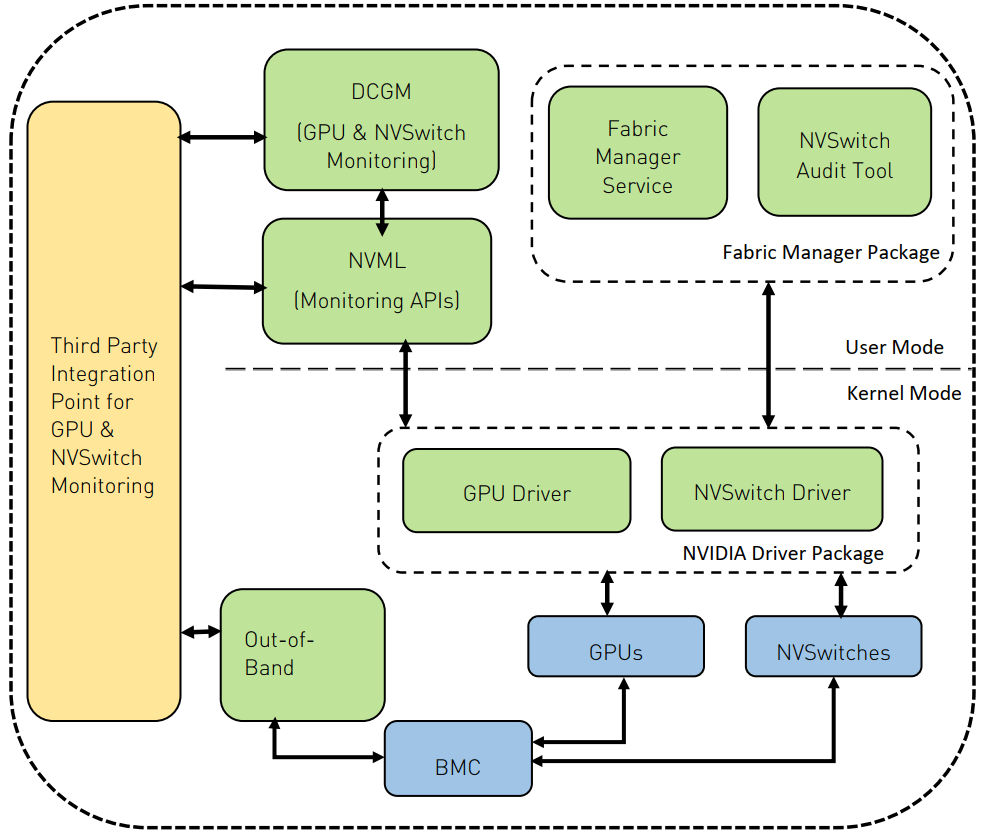
dcgmi 是 Nvidia datacenter-gpu-manager 的命令行程序,可以用来采集 GPU 各类子资源的利用率数据,揭示的数据比 nvidia-smi 更详细,也更便于对接监控系统(比如 Prometheus)。主要可用它来看模型训练过程中的 NVLink 带宽使用情况。NVIDIA GPU上存在一些硬件计数器,这些计数器可以用来收集一些设备级别的性能指标,例如GPU利用率、内存使用情况等。借助NVIDIA提供的NVML(NVIDIA Management Library)库或DCGM(Data Center GPU Manager)工具能够查询这些硬件层提供的指标。NVIDIA Data Center GPU Manager (DCGM) 是一套用于管理和监控数据中心 NVIDIA GPU 的工具集。
DCGM: nvidia data center gpu manager是一套用于在集群环境中管理和监控 NVIDIA 数据中心 GPU 的工具。它包括主动健康监控、全面诊断、系统警报和治理策略(包括电源和时钟管理)。 DCGM 诊断是一款运行状况检查工具,可以检查基本的 GPU 运行状况,包括是否存在 ECC 错误、PCIe 问题、带宽问题以及运行 CUDA 程序的常见问题。
Fieldiag压测工具
当前NV官方以fieldiag压测结果作为RMA的标准,不同的GPU都有匹配的fieldiag工具(这些工具需要在哪里进行获取?),工具可以运行在DOS环境或者大多数Linux系统kernel2.6.16 or later,
Glibc 2.32 or later, 只支持64-bit x86_64,TinyLinux version 12.08 or later is supported.
支持的NVIDIA Tesla硬件:
- Tesla C2050, C2070, C2075
- Tesla M2050, M2070, M2070Q, M2075
- Tesla S2050
- Tesla X2070, X2090
- Tesla M2090
- Tesla K10, K20, K20X, K40
NVQual
故障问题
XID消息是来自NVIDIA驱动程序的错误报告,该报告打印到操作系统的内核日志或事件日志上;xid指示GPU硬件问题,NVIDIA软件问题或用户应用程序问题;常见的xid事件:
- XID 13: GR: SW Notify Error:常见原因:一般为用户应用程序故障。通常这是一个数组下标越界错误。也有可能是非法指令,非法寄存器等其他情况。极少数情况下 会出现硬件故障或者软件错误导致XID 13
- XID 31: Fifo: MMU Error:常见原因: 一般为应用程序级别故障。 当MMU上报故障时,当gpu芯片上的应用程序进行非法地址访问时,会触发此类故障并记录。
- XID 32: PBDMA Error:常见原因: 一般是硬件问题。当 DMA 控制器报告故障时,会记录此事件,该控制器通过 PCI-E 总线管理 NVIDIA 驱动程序和 GPU 之间的通信流。这些故障主要涉及PCI的质量问题,一般不是由用户应用程序操作引起的。解决方式: 联合硬件运维处理
- XID 43: RESET CHANNEL VERIF ERROR:常见原因:基本是用户应用程序故障。不影响GPU的健康状况解决方式: 联合开发同事处理
- XID 45: OS: Preemptive Channel Removal:常见原因: 通常这并代表发生故障。用户程序退出中止,control-C cpu reset sigkill 都会导致此类事件
- XID 48: DBE (Double Bit Error) ECC Error:常见原因:怀疑硬件故障。当gpu检测到不可修正的错误,会记录该事件。
- XID 63, 64: ECC Page Retirement or ROW REMAPPING:常见原因: ECC显存故障,常见于硬件故障。 当应用程序遭遇到 GPU 显存硬件错误时,NVIDIA 自纠错机制会将错误的内存区域retire 或者 remap,retirement 和remapped 信息需要记录到 infoROM 中才能永久生效。A 系列显卡开始支持row remappingA系列之前的显卡,例如T4 V100 P100 支持dynamic page retirement解决方式:联合硬件同事排查
- XID 74: Nvlink ERROR:常见原因:多半为硬件故障。多卡GPU之间使用nvlink进行通讯时出现问题,链路故障或者g卡故障都会导致。解决方式:可自行通过gpu reset 或者重启节点 进行恢复。如果此时还无法恢复,需要进行维修处理。
- XID 79: GPU has fallen off the bus:常见原因: 多半是硬件问题。具体现象为当gpu驱动尝试通过PCI-e总线访问GPU,访问失败。此事件通常由PCIe链路上的硬件故障引起,导致GPU由于链路中断而无法访问。解决方式:硬件维修
- XID 93: Non-fatal violation of provisioned inforom wear limit:常见原因: 当GPU驱动程序因违反使用nvflash-elsesessionstart导致更新infoROM失败。大多数情况下,这并不是软件驱动故障。
- XID 94, 95: CONTAINED/UNCONTAINED ECC ERRORs:常见原因:当应用程序遭遇到 GPU 不可纠正的显存 ECC 错误时,NVIDIA 错误抑制机制会尝试将错误抑制在踩到硬件故障的应用程序,而不会让错误导致 GPU 上的所有应用程序受到影响。当抑制机制成功抑制错误时,会产生Xid 94事件,仅影响遭遇了不可纠正 ECC 错误的应用程序。 Xid95 代表抑制失败,此时表明运行在该 GPU 上的所有应用程序都已受到影响。解决方式: 联合硬件同事处理
- XID 110 SECURITY FAULT ERROR:常见原因:硬件故障。解决方式: 恢复最近所有的系统硬件修改,并冷启动系统。需联系硬件处理。
- XID 119, 120: GSP RPC Timeout / GSP Error:常见原因: 当在 GPU 的 GSP 核心上运行的代码中发生错误/或在等待 GPU 的 GSP 核心响应 RPC 消息时发生超时时。解决方式: 可以尝试重启节点或者重置GPU。如果还不行联系硬件处理
参考链接:https://docs.nvidia.com/deploy/xid-errors/index.html
国内外GPU技术发展趋势
📚 参考资料
 微信
微信 支付宝
支付宝




